asi si nerozumíme. APU mají už teď co dělat, aby se udržely na hranici hratelných fps především díky výrazné limitaci paměťové propustnosti. Tu IOT ještě dále snižuje a to především u slabých GPU nebo integrovaných GPU.(viz. AT limitation odstavec) Intel vyřešil onu paměťovou limitaci nějakým kvazi software/hardware řešením (jednotný paměťový prostor + nové DX extensions), které není úplně dokonalé, ale zřejmě funguje. AMD APU by bez nějakého podobného "smart" řešení narážela na podobné problémy, tj. zapnutí IOT by způsobilo výkonostní ztrátu, kterou naopak výkonné diskrétní grafiky tolik netrpí jak vyplývá s článku/prezentace.
Celá diskuze ale byla primárně o tom zda GCN třetí generace může podporovat IOT a vzhledem k tomu, že IOT je DX11 efekt, který má ale jisté limitace na současném DX11 API, dovolím si tvrdit,že Tonga jako DX12/HSA GPU může klidně IOT podporovat a není nutné kvůli tomu čekat na další generaci Pirate Islands. Haswell iGPU DX12 podporuje také stejně jako Tonga a také starší GCN karty a Nvidia GPUmohou IOT podporovat byť s určitými nedostatky. GCN je možná díky Mantle ve výhodě,protože Mantle (jak tvrdí AMD) umožní i takové efekty, které v DX nejsou zatím možné.
HEAD píše:NDA by melo vyprset ve 14:00.
Zase se to amd podarilo.Absolutne zadnej leak niceho.
Jakto že žádný leak?
Specifikace jsou už dávno venku, "oficiální" výkon také (3DM firestrike, BF4...).
Chybí akorát recenze a ty většinou vycházejí až po NDA.
Když je to takova "kopie", proc AMD nemá podobnou spotřebu, vykon a frekvence jako Maxwell ? No asi to takova "kopie" není. Maximalne mozna urcita podobnost. Plnou Tongu uz by taky mohli vydat, at se to da konecne srovnat.
Však má podobnou spotřebu. I Ache postoval reálné hodnoty TDP v Maxwell vlákně
Ache píše:Mimochodem TDP limity referenční GTX980 jsou podle biosu 180W/225W (+125%). Takže těch 165W je jen taková vycucaná hodnota (asi average spotřeba i při zásahu temp-limitu)....
Jinak tady nejde o podobnost ve spotřebě, ale v uArch, tedy stavbě a uspořádání bloků
Tonga to support is the last function of the far right "GPU compute context switch (GPU Compute Context Switch)" and "GPU graphics preemption (GPU Graphics Preemption)" and the like. This means that in Tonga, AMD has reached the GPU architecture which is the goal of the HSA finally. At the stage where the GPU core of Tonga generation has been integrated into the APU, HSA architecture is perfected.
Flexible context switch CPU like
At present, AMD does not claim to innovation in the HSA on the roadmap of Tonga but, Tonga's GPU core is the key to the end of the HSA in practice. One of the challenges of the current GPU is that flexible context switching is not possible. It is not possible while it is running a certain context, and switch to another context is interrupted. It is not possible to switch the context to be finished only from running all the kernel once. It does not have a mechanism that loads the context that was stored again when it was stored in the memory context you are running, load another context, and returns from the context.
Therefore, it is not possible to support virtualization flexibility in the GPU compute current GPU. Because if the graphics processing, the context would be flushed at the stage you draw a frame, there is no problem. However, the GPU compute, since it can not be switched during execution kernel, virtualization practical difficulty. The Tonga core and later, this issue is finally resolved, context switching of the CPU-style becomes possible. Context switch is controlled by hardware as well as the CPU.
Incidentally, AMD GPU current can cause context calculation in parallel up to 8. It also has become a context control, such as multi-core CPU, support 2 context (= 2 page table) can be in (Compute Unit) for each CU. In other words, I can reduce the granularity of context than CU. It is also to NVIDIA implementing context switching by Maxwell (Maxwell) generation, it is not enabled or currently implemented yet.
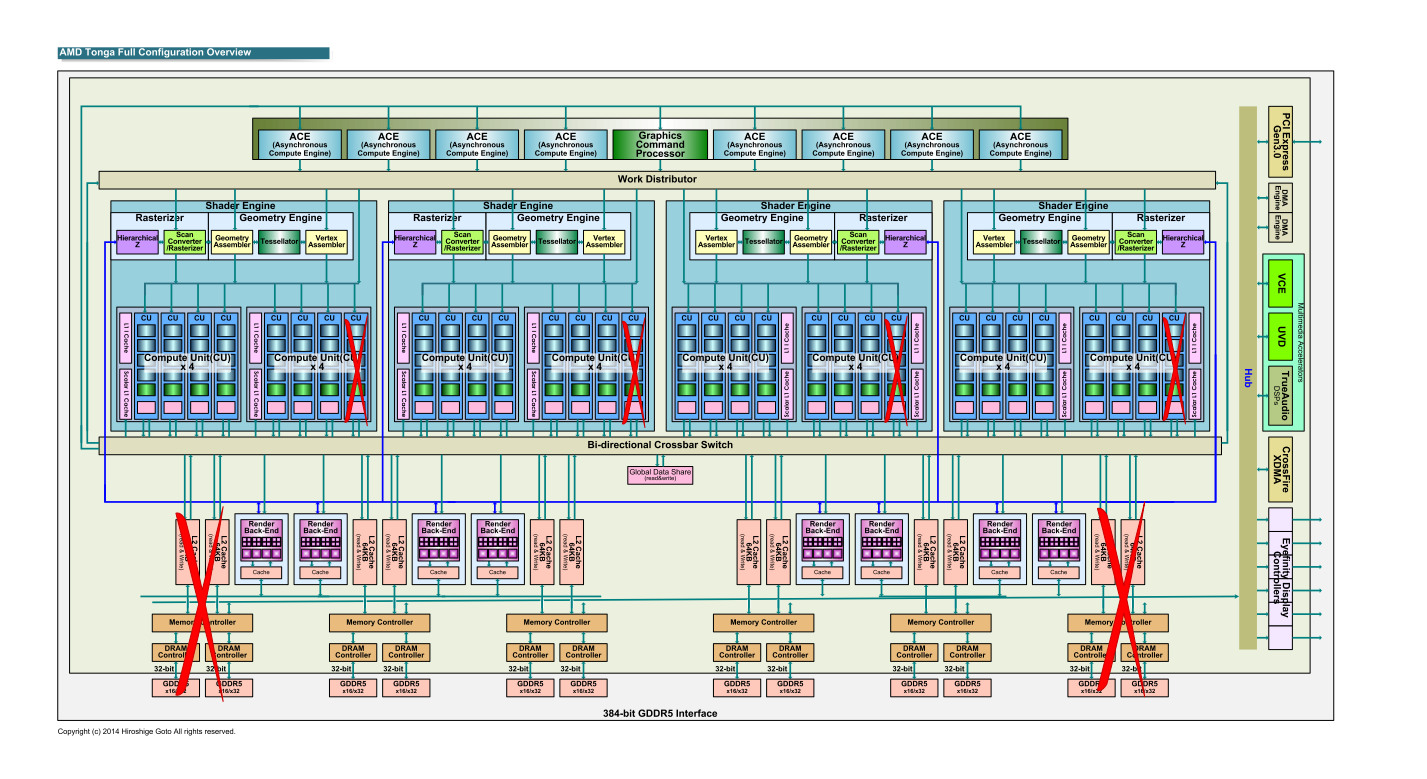
We do not know the ROP has been implemented (Rendering Output Pipeline), whether the same as the 32 units (Radeon HD 7900) Tahiti, is whether the 48 units that correspond to the memory controller. ROP clusters correspond one-to-two or one-to-one to the memory controller normally. However, because the AMD is to allow the previous arrangement of irregular 1: 1.5, the possibility of the same unit 32 Tahiti is high. However, for performing memory bandwidth compression in Tonga, is not without the possibility of unit 48.
Jak se zdá, tak plná verze Tongy se neobjevila z toho důvodu, že ty nejlepší jádra AMD rezervovala pro Apple.
On the off chance I sent him an email asking about the frequency, number of SPs, ROPs etc, to which he kindly sent me a chart (that compared it with various other AMD GPUs) and added- "I found this table that gives some of that info. The only correction I would make is that the M295X in the iMac has a core clock of 850MHz, according to Luxmark. Also it has 32 Compute Units".
I personally believe Tonga is a GPU primarily for Apple and FirePro. It is the higher-end m295x for iMac, possibly replacing the D300/500/700 in Mac Pro, and as the w7100 FirePro. All the lesser-binned products can be used as cheap R9 285s (selling leftover chips that don't make the cut - there will be plenty)
Tohle neni poprvé co se leze Applu do zadku. Dam několik příkladů z minulosti co se netýkaj AMD a přesto se staly.
První příklad, zapoměl jsem název firmy kterou to stálo život, ale je to ještě z dob power čipů. Při stárnoucí G4ce v laptoptech a nemožnosti portnout nenažranou G5tku do mobile segmentu stál apple před problémem. G4ka sice stále stačila protože v x86 sféře bojovala K7 s Netburstem, ale kor výhled K8 a dále nevěstil nic dobrého, IBM architekturu tlačila mainframe only už neměla zájem do budoucna dělat ekonomické desktop či laptop čipy. Takže Apple stál před problémem, dělat na tom sám nebo přejít na x86. Nakonec se rozhodl přejít na x86 a první experimenty začaly už v době netburstů, nakonec přešel poprvé s core1 a vše přešlo s Core2. Nicméně už v době kdy měl rozhodnuto nechal vyvíjet vylepšenou G4 s featurkama z G5. Apple nakonec zakázku nezaplatil, vše odmítl protože šel na x86, ta firma pak dříve než stihl začít soud krachla a Apple jí koupil celou za zlomek ceny.
Další příklad, doba Core2 a vrcholu Nvidie v chipsetech. Nvidia tehdy připravovala po úspěchu slabého Ionu další chipset, architektura ale vycházela z prvních DX10 40nm čipů a čip měl mít 48 SP! Tzn bejt 3x silěnší než původní ION, na tu dobu pro integrovanou grafiku šílenej výkon, ala deklasoval by jakoukoliv integrovanou grafiku do příchodu APU. Problém bylo že slabej Atom neuživil ani onen ion, a vejš byly dedikovaný grafiky, takže Nvidia nakonec tento projekt dokončila, ale podepsala exkluzivitu pro Apple a tento chipset existoval ale montoval se jen do poslední Core2 based Airů s NV chipsetem, myslim možná i do některejch mac mini. IGP v nich je silnější než cokoliv co NV kdy vydala do x86 sféry.
Poslední příklad uvedu Intel Iris grafiku s 128MB L4 pro framebuffer. Testy ukázaly že byla rychlejší ak APU od AMD, nicméně slabá penetrace a cenová politika Intelu nebyly způsobený jen Intelem, nicméně také tím že opět kejvnul na exkluzivitu pro apple a Intely s Iris se dodávaly asi půl roku prakticky výhradně pro haswell-based mobilní macy. To samé thunderbolt, rovněž byl dlouho exclusive pro Apple což napomohlo jeho mizernému rozšíření. To samé předtim rychlej Firewire 800. Krom mac světa to nepoužíval snad nikdo, přičemž kdyby se to rozšířilo nikdo by ever nepotřeboval USB 3.0, to poroti tomu i po tolika letech vypadá (a je) shit rozhraní.
Tudiž AMD v tom neni zdaleka samo kdo se nechal Applem svázat do dohodou, stylu radši ztratim část trhu a neuvedu dobrej produkt kterej mam v kapse než abych řekl ne oh velkému božskému Applu.
Takze plne jadro ma jen 2048sp... cili zazraky se nekonaji. O moc vetsi vykon nez na stare 280X se neda cekat, pokud vubec 285X v desktopu bude. Ani se nedivim, ze tyhle jadra radsi prodaji applu, nez aby je montovali na VGA, co budou jen hnit nekde na sklade.
Podle něj se ale bohužel nedá skoro nic usuzovat, zkus si jej na desktopu. Většinu času bude GPU load malej půjde jen o to jak si driver poradí s požadavky geometrie, je to jak jiné profi OGL aplikace. Kor to nejde srovnávat vs mac kde je samo sebou cinebench jinej, jinej OS, jiný drivery a na těchto OS jde prakticky jen o driver, ala je hezký že máme srovnání se 780TI která pro mac vůbec neexistuje a někdo jí tam rozjel tak že jí připojil do PROčka nebo nedejbože přes hackintosh či tunderbolt a skrze modlej driver.
Dotyčný by měl zkusit nahrát win na ten novej Imac, pokud teda win driver AMD tuhle kartu podporuje. Pak by stačilo vzít prodejnou tongu hodit jí na stejný takty a porovnat rozdíl.